El primer conjunto de datos mejor ajustado es quizás el más conocido y sólido de todos las ditribuciones de leyes de potencia: la frecuencia de uso de las palabras en el idioma inglés. Los datos específicos utilizados son las frecuencias del uso de las palabras en la novela de Herman Melville “Moby Dick”.
El segundo, moderadamente apropiado conjunto de datos es el número de conexiones que tiene cada neurona en el gusano nematodo C. elegans.
El último, los datos inadecuados son el número de personas afectadas por apagones en los Estados Unidos entre 1984 y 2002.
def plot_basics(data, data_inst, fig, units):from powerlaw import plot_pdf, Fit, pdf# from mpl_toolkits.axisartist import Subplot # no lo usas, lo puedes borrar annotate_coord = (-.4, .95) ax1 = fig.add_subplot(n_graphs, n_data, data_inst) x, y = pdf(data, linear_bins=True) ind = y >0 y = y[ind] x = x[:-1] x = x[ind] ax1.scatter(x, y, color='r', s=.5) plot_pdf(data[data >0], ax=ax1, color='b', linewidth=2)from pylab import setp setp(ax1.get_xticklabels(), visible=False)if data_inst ==1: ax1.annotate("A", annotate_coord, xycoords="axes fraction", fontproperties=panel_label_font)# 👇 CAMBIO IMPORTANTE AQUÍfrom mpl_toolkits.axes_grid1.inset_locator import inset_axes ax1in = inset_axes(ax1, width="30%", height="30%", loc=3) ax1in.hist(data, color='b') ax1in.set_xticks([]) ax1in.set_yticks([]) ax2 = fig.add_subplot(n_graphs, n_data, n_data + data_inst, sharex=ax1) plot_pdf(data, ax=ax2, color='b', linewidth=2) fit = Fit(data, xmin=1, discrete=True) fit.power_law.plot_pdf(ax=ax2, linestyle=':', color='g') p = fit.power_law.pdf() # (no lo usas, pero no molesta) ax2.set_xlim(ax1.get_xlim()) fit = Fit(data, discrete=True) fit.power_law.plot_pdf(ax=ax2, linestyle='--', color='g') setp(ax2.get_xticklabels(), visible=False)if data_inst ==1: ax2.annotate("B", annotate_coord, xycoords="axes fraction", fontproperties=panel_label_font) ax2.set_ylabel(u"p(X)") ax3 = fig.add_subplot(n_graphs, n_data, n_data *2+ data_inst) fit.power_law.plot_pdf(ax=ax3, linestyle='--', color='g') fit.exponential.plot_pdf(ax=ax3, linestyle='--', color='r') fit.plot_pdf(ax=ax3, color='b', linewidth=2) ax3.set_ylim(ax2.get_ylim()) ax3.set_xlim(ax1.get_xlim())if data_inst ==1: ax3.annotate("C", annotate_coord, xycoords="axes fraction", fontproperties=panel_label_font) ax3.set_xlabel(units)
Calculating best minimal value for power law fit
Calculating best minimal value for power law fit
Calculating best minimal value for power law fit
xmin progress: 99%
Linea punteada representa con xmin de 1.
Linea segmentada representa un xmin estimado
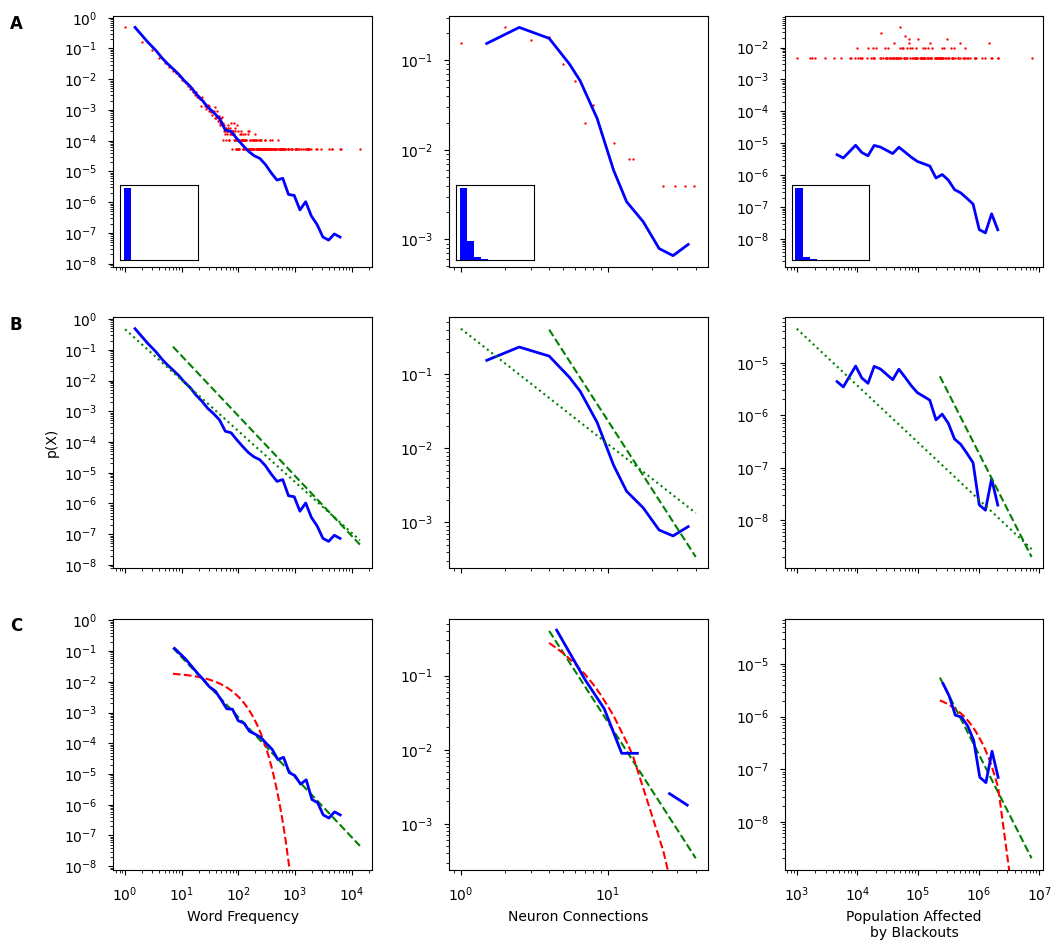
Pasos básicos de análisis para distribuciones de cola pesada: visualización, ajuste y comparación.
Los datos de ejemplo para el ajuste de la ley de potencia son: buen ajuste (columna izquierda), ajuste medio (centro columna) y mal ajuste (columna derecha).
Visualizando datos con funciones de densidad de probabilidad. Un histograma típico en ejes lineales (recuadros) no es útil para visualizar distribuciones de cola pesada. En los ejes log-log, es necesario utilizar contenedores (bins) espaciados logarítmicamente para representar datos (linea azul). Los contenedores espaciados linealmente (línea roja) ocultan la cola de la distribución (ver paper).
Ajuste a la cola de la distribución. El mejor ajuste de ley de potencia solo puede cubrir una parte de la cola de la distribución. Línea verde punteada: la ley de potencia se ajusta a partir de xmin=1 . Línea verde discontinua: ley de potencia ajuste desde el \(x_{min}\) óptimo (consulte Métodos básicos: Identificación del rango de escala).
Comparando la bondad del ajuste. Una vez que se establece el mejor ajuste a una ley de potencia, la comparación con otras posibles distribuciones son necesarias. Línea verde discontinua: ajuste de la ley de potencia a partir del \(x_{min}\) óptimo. Línea roja punteado: ajuste exponencial a partir del mismo \(x_{min}\).
blackouts = blackouts/10**3
Introducción
data = blackouts####import powerlawfit = powerlaw.Fit(data)fit.power_law.alphafit.power_law.sigmafit.distribution_compare('power_law', 'exponential')
Calculating best minimal value for power law fit
xmin progress: 99%
(12.754562675882063, 0.1522925560442657)
data = words####import powerlawfit = powerlaw.Fit(data)fit.power_law.alphafit.power_law.sigmafit.distribution_compare('power_law', 'exponential')
Calculating best minimal value for power law fit
xmin progress: 99%
(3809.7804237111686, 2.753965722517646e-23)
data = worm####import powerlawfit = powerlaw.Fit(data)fit.power_law.alphafit.power_law.sigmafit.distribution_compare('power_law', 'exponential')
Calculating best minimal value for power law fit
xmin progress: 93%
(16.601134166691274, 0.0005788608926042935)
Devuelve el log-likelihood* ratio, y su valor p , entre los dos ajustes de distribución, asumiendo que las distribuciones candidatas están anidadas.
Si es mayor que 0, se prefiere la primera distribución. Si es menor que 0, se prefiere la segunda distribución.
*El likelihood cuantifica qué tan bueno es un modelo, dado un conjunto de datos que se han observado.
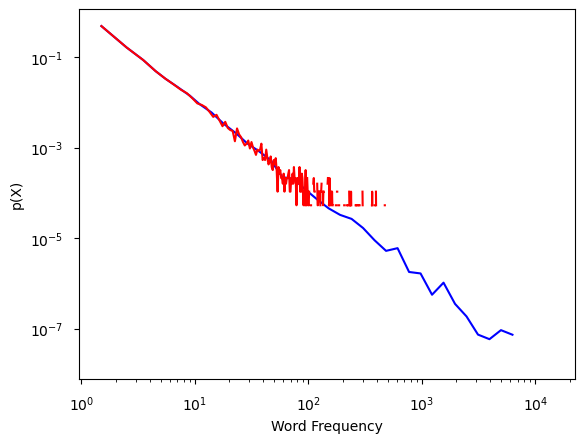
Las PDF requieren bining en los datos, y al presentar una PDF en ejes logarítmicos, los contenedores deben tener espaciado logarítmico (anchos exponencialmente crecientes).
Aunque los contenedores lineales mantienen una alta resolución en todo el rango de valores, la probabilidad muy reducida de observar valores grandes en las distribuciones dificulta una estimación confiable de su probabilidad de ocurrencia.
Esto se compensa utilizando bins logarítmicos, lo que aumenta la probabilidad de observar un rango de valores en la cola de la distribución y normalizando apropiadamente para ese aumento en el ancho del contenedor.
Calculating best minimal value for power law fit
xmin progress: 99%
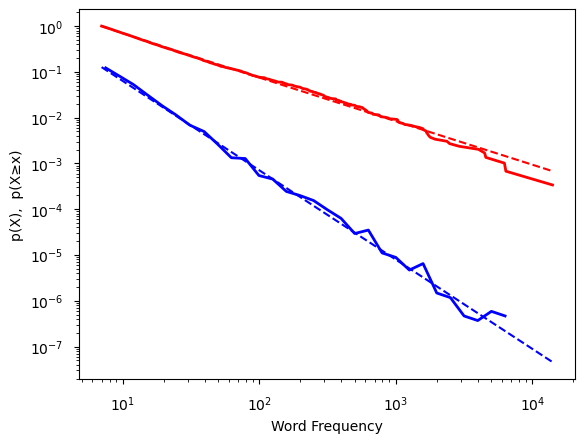
Otra forma de extraer información sobre la cola de la distribución es usando la Distribución acumulada complementaria, donde:
\(p_k = \sum\limits_{q = k + 1}^\infty {p_q }\)
Donde si \(p_k\) sigue una ley de potencia: \(p_k \sim k^{ - \gamma }\), se cumple que:
\(CDF(k) \sim k^{ - \gamma + 1}\)
Función de densidad de probabilidad \((p (X)\), azul) y
Función de distribución acumulativa complementaria \((p (X ≥ x)\), roja) de las frecuencias de palabras de “Moby Dick”.
\(CCDF=(1−CDF(x))\)
data = blackoutsfit = powerlaw.Fit(data)###x, y = fit.cdf()bin_edges, probability = fit.pdf()y = fit.lognormal.cdf()#data=[300,350]y = fit.lognormal.pdf()
Calculating best minimal value for power law fit
xmin progress: 99%
Identificando el rango de escalamiento (de la ley de potencia)
El primer paso para ajustar una ley de potencia es determinar en qué parte de los datos se ajustará una cola pesada.
Una característica interesante de la distribución es la cola pesada son su cola y sus propiedades, por lo que si los valores iniciales, pequeños de los datos no siguen una distribución de ley de potencia, el usuario puede optar por ignorar dichos datos.
La pregunta es de que valor mínimo xmin comienza la relación de escala de la ley de potencia?. Los métodos de [5] (ver paper) encuentran este óptimo, el valor de xmin, al crear un ajuste de ley de potencia a partir de cada valor único en el conjunto de datos, luego seleccionando el que resulta en la distancia mínima de Kolmogorov-Smirnov, D, entre los datos y el ajuste.
Si el usuario no proporciona un valor para xmin, Powerlaw calcula el valor óptimo cuando el objeto Fit se crea por primera vez. Como las leyes de potencia no están definidas para x = 0, debe haber algún valor mínimo. Por lo tanto, incluso si un determinado conjunto de datos trae consigo un razonamiento específico del dominio de que los datos deben seguir una ley de potencia en todo su rango, el usuario todavía debe dictar un xmin. Esto podría ser un mínimo teórico, un umbral de ruido, o el valor mínimo observado en los datos. La Figura 1B visualiza la diferencia de ajuste entre la asignación xmin = 1 y encontrar el xmin óptimo minimizando D
data = blackouts####import powerlawfit = powerlaw.Fit(data)print(':')print(fit.xmin)print(fit.fixed_xmin)print(fit.alpha)print(fit.D)print('---------')fit = powerlaw.Fit(data, xmin=1.0)print(fit.xmin)print(fit.fixed_xmin)print(fit.alpha)print(fit.D)
Calculating best minimal value for power law fit
:min progress: 99%
230.0
False
2.272637219830288
0.0606737962944387
---------
1.0
True
1.220176593367261
0.37601504850371725
data = blackouts####fit = powerlaw.Fit(data)#, xmin=(250.0, 300.0)fit.fixed_xminfit.given_xminfit.xmin
Calculating best minimal value for power law fit
xmin progress: 99%
230.0
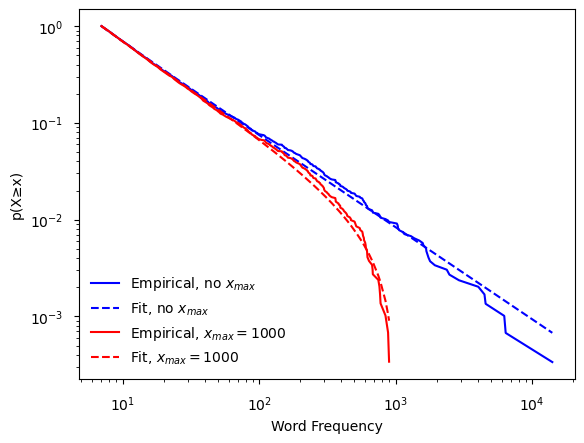
Un límite superior también podría deberse a la escala de tamaño finito, en la que los datos observados provienen de una pequeña subsección de un sistema más grande.
El tamaño finito de la ventana de observación significaría que los puntos de datos individuales no podrían ser más grandes que dicha ventana, xmax, aunque el sistema mayor tendría datos más grandes, no observados (por ejemplo, en neurociencia, grabados desde un trozo de corteza vs todo el cerebro).
Los efectos de tamaño finito se pueden probar variando experimentalmente el tamaño de la ventana de observación (y xmax) y determinando si los datos siguen una ley de potencia con el nuevo xmax [3, 4] (ver paper). La presencia de un límite superior se basa en la naturaleza de los datos y el contexto en el que se recopilaron, por lo que solo puede ser dictada por el usuario. Cualquier dato por encima de xmax se ignora para el ajuste.
data = blackoutsfit = powerlaw.Fit(data)print(':')print(fit.xmax)print(fit.fixed_xmax)####fit = powerlaw.Fit(data, xmax=10000.0)print(':')print(fit.xmax)print(fit.fixed_xmax)
Calculating best minimal value for power law fit
:min progress: 99%
None
False
Calculating best minimal value for power law fit
:min progress: 99%
10000.0
True
Figura 3
Para calcular o trazar CDF, CCDF y PDF, de forma predeterminada, los objetos Fit solo usan datos por encima de xmin y por debajo de xmax (si están presentes).
Los comandos de ploteo del objeto Fit pueden trazar todos los datos que se le dieron originalmente con el key original_data = True. Los objetos Distribution constituyentes solo se definen dentro del rango de xmin y xmax, pero pueden plotear cualquier subconjunto de ese rango pasando datos específicos con el key data.
Cuando se utiliza un xmax, el CDF y el CCDF de una ley de potencia no muestran una línea recta en un gráfico log-log, sino que se inclinan hacia abajo cuando se acercan al xmax (Figura 3). La PDF, en contraste, aparece como una línea recta en todo el rango hasta xmax. Debido a esta diferencia, las PDF son preferibles cuando se visualizan datos con un xmax, a fin de no oscurecer la escala.
Calculating best minimal value for power law fit
Calculating best minimal value for power law fit
xmin progress: 91%
/Users/crcandia/anaconda3/envs/candialab2/lib/python3.10/site-packages/powerlaw.py:1195: RuntimeWarning: divide by zero encountered in scalar divide
C = 1.0/C
/Users/crcandia/anaconda3/envs/candialab2/lib/python3.10/site-packages/scipy/optimize/_optimize.py:851: RuntimeWarning: invalid value encountered in subtract
np.max(np.abs(fsim[0] - fsim[1:])) <= fatol):
xmin progress: 99%
/Users/crcandia/anaconda3/envs/candialab2/lib/python3.10/site-packages/powerlaw.py:840: RuntimeWarning: invalid value encountered in multiply
likelihoods = f*C